

W trakcie swojej kariery przeprowadziłem audyty SEO dla setek domen. Ich ogólna zawartość, szablon i najważniejsze elementy zmieniały się z czasem ze względu na potrzeby klienta, ale także moje doświadczenia. Dziś uważam, że każdy audyt SEO powinien być inny i dostosowany do danego projektu. Oczywiście są w nim elementy stałe, których nie powinniśmy pomijać, ale na koniec dnia raport powinien przynieść maksymalną korzyść w kontekście konkretnego projektu. Dla każdej firmy i domeny inne aspekty audytu SEO będą najważniejsze, a priorytety i nacisk na poszczególne zadania musi brać pod uwagę specyfikę działalności danej organizacji.
Analiza aktualnej widoczności, najważniejszych słów kluczowych i okazji do szybkiej optymalizacji
Jeśli nazwiemy audyt „audytem technicznym” może być to krok, który pomijamy. Interesuje nas wtedy techniczna sytuacja strony i ocena jej działania pod kątem tego co jest w stanie zobaczyć robot wyszukiwarki.
Jednak kiedy audyt ma dotyczyć wszystkich aspektów SEO jest to moim zdaniem krok od którego powinniśmy zacząć.
Zanim zaczniemy wprowadzać jakiekolwiek optymalizacje i zmiany na stronie musimy wiedzieć jak wygląda aktualna sytuacja i jakie słowa kluczowe przynoszą nam ruch. Musimy przede wszystkim zadbać o to, aby nasza strona nie straciła przy okazji optymalizacji, a jak wiemy lepsze jest wrogiem dobrego.
Sprawdzić to powinniśmy przede wszystkim w Google Search Console podłączonym do naszej strony oraz zewnętrznych narzędziach takich jak Senuto, Ahrefs czy Semrush. Wszystkie pozwolą nam na wygenerowanie listy słów kluczowych (mniej lub bardziej dokładnej) z oceną ich pozycji w Google i potencjalnego lub realnego ruchu, który uzyskujemy dzięki ich obecności w wynikach wyszukiwania.
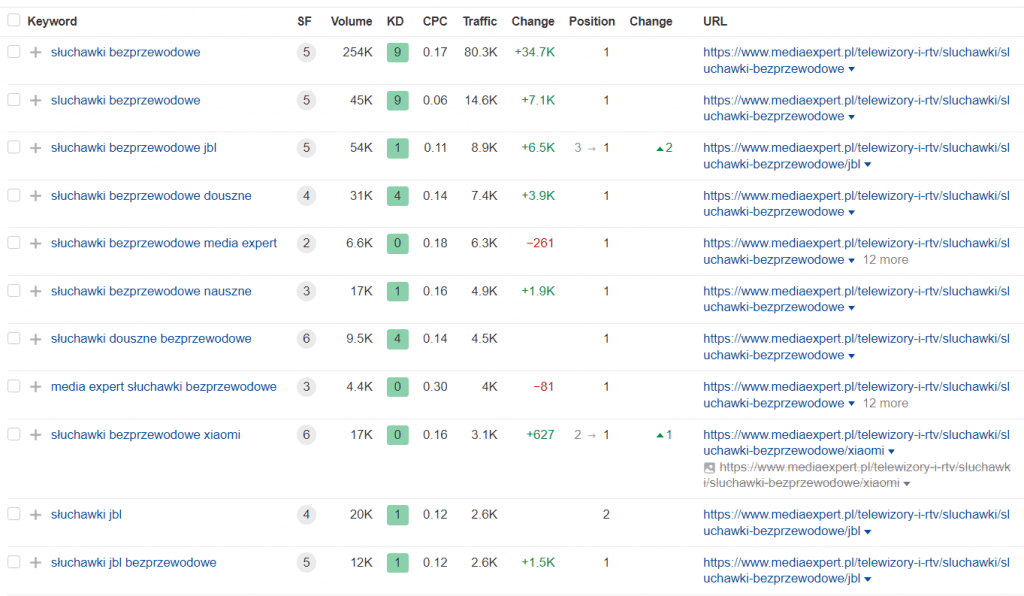
Oczywiście możemy tam znaleźć słowa, które przynoszą nam ruch i są na wysokich pozycjach, ale w drugiej kolejności powinniśmy sprawdzić te słowa kluczowe, które jeszcze dziś nie są dla nas ważne, ale mają w sobie spory potencjał.
Jeśli widzimy, że dane słowa kluczowe generują wyświetlenia, ale nie generują kliknięć to powinniśmy zastanowić się jak zoptymalizować naszą stroną, aby poprawić ich pozycje (realnie tylko bardzo wysokie pozycje w okolicach TOP3 gwarantują ruch) lub jak zwiększyć CTR (jeśli pozycja jest wysoka, ale użytkownicy nie klikają w nasz link może to wymagać od nas zmiany meta-title czy meta-description).
Na końcu widzimy słowa, które prawdopodobnie są tak daleko w wynikach wyszukiwania, że na dzień dzisiejszy nie mamy szans szybkiej optymlizacji ich pozycji. Należy je jednak zapamiętać i spróbować przygotować długofalową strategię contentową, która będzie zawierała w sobie treści odpowiedzialne za potencjalną poprawę tych pozycji. Niezależnie czy będziemy optymalizować istniejące treści czy tworzyć nowe zawsze warto próbować walczyć o nowe słowa kluczowe.
Analiza indeksowania strony i udostępnienia zawartości strony robotom wyszukiwarek
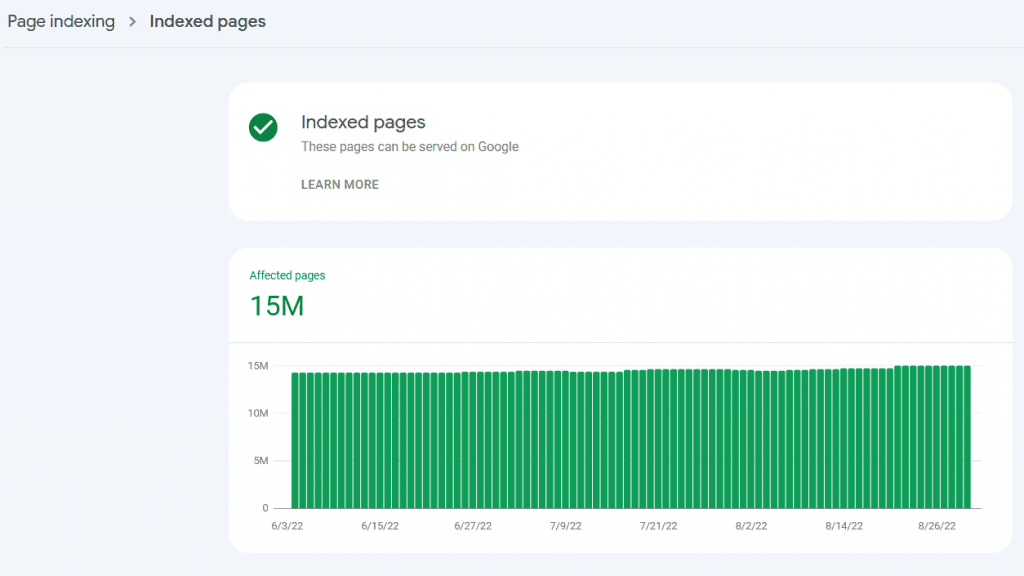
W tym kroku niezbędnym będzie wykonanie pełnego crawlu strony (co może być trudne dla bardzo obszernych stron pod kątem ilości adresów URL). Uzupełnieniem tego kroku powinna być również bardzo dokładna analiza Google Search Console i zakładki „Indeks”->”Stan”.
Oba zadania mają na celu pełne poznanie strony pod kątem indeksacji wszystkich adresów URL. Musimy sprawdzić czy wszystkie adresy, które powinny znajdować się w Google są odblokowane do indeksacji (w pliku robots.txt, sekcji head za pomocą meta-robots czy X-Robots-Tag) i czy Google rzeczywiście bierze je pod uwagę. Część z adresów URL na naszej stronie nie powinna znaleźć się w indeksie co wymusza na nas ich odpowiednie zablokowanie. Wartościowe adresy URL nie powinny również zwracać błędów 404 (lub innych) czy przekierowań.
Cały proces jest dość skomplikowany i ma nam umożliwić indeksację wszystkich adresów, które powinny wyświetlać się w wyszukiwarce.
Analiza wersji mobilnej strony
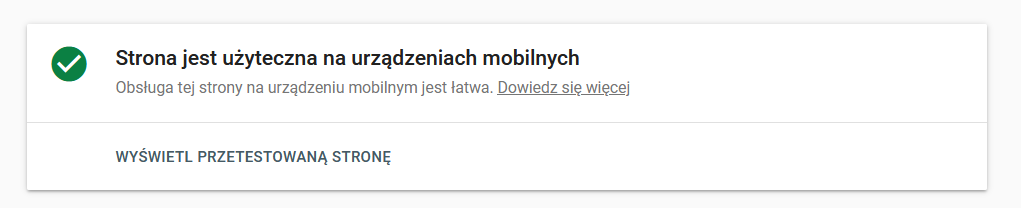
Od kiedy większość ruchu internetowego odbywa się za pomocą urządzeń mobilnych krytycznie ważne jest przygotowanie wersji mobilnej naszej strony (czy to za pomocą oddzielnej wersji na subdomenie czy szablonu RWD). Mobilna wersja wyszukiwarki to wartościowe źródło ruchu i powinniśmy się upewnić, że zarówno użytkownicy, jak i roboty nie mają problemów z odczytywaniem informacji na naszej stronie w wersji na smartfony czy tablety.
Z pomocą w tym idzie nam Test Optymalizacji Mobilnej od Google (https://search.google.com/test/mobile-friendly) dla szybkiej weryfikacji oraz Google Search Console dzięki zakładce „Eksperymenty i personalizacja”->”Obsługa na urządzeniach mobilnych”, gdzie otrzymamy informację z podziałem na konkretne adresy URL.
Analiza linkowania wewnętrznego, przekierowań, błędów, adresów URL czy odpowiednich linków canonical
Linkowanie wewnętrzne to sposób w jaki nie tylko użytkownicy poruszają się po Twojej stronie, ale również roboty wyszukiwarek. Z obu tych powodów powinniśmy zadbać o jak najwyższą jakość linkowania wewnątrz naszej witryny.
Po pierwsze nie powinniśmy linkować do stron błędów. Jeśli crawler znajdzie takie linki musimy zamienić je na działające lub usunąć. Podobnie sprawa wygląda w kontekście linków to przekierowań. Powinniśmy zamienić je na docelowe adresy, aby skracać drogę dla robotów wyszukiwarek.
Adresy URL powinny być również tworzone w sposób przyjazny zarówno dla użytkowników, jak i robotów wyszukiwarek. Chodzi o to, aby adres URL w prosty sposób wskazywał w jakim miejscu strony się znajdujemy. Tajemnicze adresy URL z ciągiem losowych znaków nie są mile widziane zarówno pod kątem SEO, jak i UX.
Kolejny aspekt to poszukiwania zduplikowanych adresów URL o tej samej treści czy ustalenia ostatecznej wersji canonical danego adresu. Tego typu problemy zdarzają się przede wszystkim na stronach, które przechodziły zmiany, zostały mocno przebudowane lub są sklepami internetowymi z dużą ilością paginacji i filtrów. Chcemy udostępnić robotom wyszukiwarek tylko wartościowe podstrony w konkretnej wersji, z konkretnym contentem, a nie przypadkowe adresy, które powstały ze względu na błędne zarządzanie lub sposób działania silnika strony.
Ostatnim przykładem optymalizacji linkowania wewnętrznego jest upewnienie się co do ilości linków kierujących do konkretnych podstron. Nie chcemy, aby na stronie znalazły się tzw. Orphan Pages, które nie posiadają żadnych linków wewnętrznych. Z drugiej strony chcemy, aby ilość linków wewnętrznych odpowiadała mniej więcej strukturze i naszym priorytetom. Im strona bardziej priorytetowa tym więcej linków wewnętrznych powinna mieć – dodatkowo można optymalizować również anchory tych linków w celu lepszego powiązania ze słowami kluczowymi.
W tym wszystkim mogą pomóc crawlery stron internetowych.
Ocena najważniejszych elementów treści takich jak meta-title, meta-description, nagłówki Hx
Tego typu analiza w swojej podstawowej wersji jest bardzo prosta. Prawie każdy crawler umożliwia szybką weryfikację meta-title, meta-description i nagłówków Hx. Możemy tam sprawdzić jak długie są elementy tytułu i opisu, a następnie zaplanować ich dostosowanie do wymagań Google. W kontekście nagłówków pozwoli nam to ocenić ich strukturę i fakt czy rzeczywiście są użyte do adekwatnych elementów tekstu.
Oczywiście oprócz analizy ilościowej powinniśmy sprawdzić jakość tych elementów czy obecność słów kluczowych.
Rozbudowana analiza treści, jakości, występowania słów kluczowych czy duplikacji
Google to nadal w głównym stopniu wyszukiwarka tekstowa. Oczywiście jest coraz bardziej rozbudowana, posiada nowe funkcje, popularność zyskuje wyszukiwanie głosowe, ale duża część aktywności użytkownika nadal odbywa się w tradycyjnym okienku Google. Dlatego też to treści nadal są w centrum działań związanych z SEO. Każdy specjalista ds. pozycjonowania rozpoczyna swoją pracę od analizy słów kluczowych, analizy treści i duplikacji.
Oczywiście coraz łatwiej zrobić szybką analizę takimi narzędziami jak Surfer czy Contadu, ale nadal jest do dość długotrwały proces – szczególnie pod kątem znalezienia odpowiednich fraz na które chcemy się wyświetlać.
Nie każdy audyt SEO zawiera tego typu analizę zawartości – nie jest to standard. Nie zrobimy tego przy okazji crawlowania strony. Musimy to robić podstrona po podstronie, a zbiorowa analiza nie wchodzi tutaj w grę.
Łatwiej jest wyłapać problemy związane z duplikacją treści – tutaj nawet podstawowy audyt strony za pomocą Ahrefs powinien wskazać nam kopie podstron.
Analiza linków przychodzących i wychodzących
Analiza linków wychodzących powinna polegać na sprawdzeniu wszystkich odnośników wychodzących poza domenę. Musimy znać ich liczbę – którą warto ograniczać. Oczywiście nie chodzi o to, aby linków wychodzących nie było w ogóle, ale o to żeby były one potrzebne użytkownikom i najlepiej linkowały wartościowe źródła, a nie przypadkowe treści. Warto część z nich zablokować atrybutem „nofollow”. Niektórzy zarekomendują używanie tego atrybutu dla wszystkich linków wychodzących. Jest to kwestia podejścia do działań SEO. Osobiście uważam, że linki wychodzące do bardzo mocnych źródeł mogą być odblokowane.
Analiza linków przychodzących jest już trochę trudniejsza. Powinien pomóc tutaj Ahrefs lub Majestic. Powinniśmy przeanalizować liczbę linków przychodzących, sprawdzić jakie domeny kierują na naszą stronę, czy linki wyglądają naturalnie i są przydatne użytkownikom, czy nie są to linki tworzone automatycznie w formie SPAMu. Najgorsze linki można zablokować za pomocą narzędzia Disavow z Google Search Console. Warto mieć świadomość co kieruje do naszej domeny nawet jeśli czasami nie możemy z tym nic zrobić.
Porównanie do profilu linkowego konkurencji również będzie wartościowe. Dzięki temu będziemy wiedzieli jak wyglądamy na tle najlepszych stron w sieci i ile nam jeszcze do nich brakuje.
Analiza obecności danych strukturalnych na stronie
Występowanie na stronie danych strukturalnych można sprawdzić w prosty sposób pod adresem: https://validator.schema.org/. Wystarczy podać dokładny adres URL i otrzymamy informację na temat użytych danych strukturalnych, ewentualnych błędów i ostrzeżeń, a także miejsca i sposobu wdrożenia tego rozwiązania.
Dane strukturalne pomagają robotom wyszukiwarki lepiej zrozumieć treści znajdujące się na stronie. Ich brak to aktualnie spory problem w kontekście optymalizacji i warto dodać ich maksymalnie dużo. Biblioteka dostępna pod adresem schema.org jest spora i regularnie się powiększa.
Najpopularniejsze rodzaje danych strukturalnych to między innymi:
- Product – oznaczenie produktów w sklepie internetowym. Pozwala na bogatsze wyświetlanie wyników wyszukiwania w Google dotyczących asortymentu naszego sklepu. Możemy tam zobaczyć ocenę produktu, jego cenę, dostępność w sklepie i inne najważniejsze informacje na jego temat.
- Article – Typowy rodzaj danych strukturalnych dla artykułów blogowych. Oznaczymy tam między innymi tytuł, treść, datę publikacji czy autora.
- Breadcrumb – Dane strukturalne, które powinny się znaleźć na każdej podstronie naszego serwisu w celu podania dokładniej ścieżki od strony głównej do podstrony na której jesteśmy. Powinna ona odzwierciedlać architekturę naszej strony.
- FAQ – Dane strukturalne dla sekcji pytań i odpowiedzi. Bardzo ważna w kontekście wyszukiwania głosowego czy sekcji „Podobne pytania” w wynikach Google.
- Logo – Jak sama nazwa wskazuje proste oznaczenie logotypu naszej firmy.
- SearchAction – Możliwość oznaczenia wewnętrznej wyszukiwarki na naszej stronie, które może pojawić się w wynikach wyszukiwania w przypadku zapytań brandowych.
- Organization – Informacje dotyczące naszej firmy.
- Website – Bardzo proste informacje dotyczące naszej strony czy profili na portalach społecznościowych.
Jeśli nie wiesz jak wdrożyć czy przygotować dane strukturalne to w pierwszej kolejności sprawdź wytyczne Google https://developers.google.com/search/docs/advanced/structured-data/intro-structured-data?hl=pl, a następnie narzędzie do generowania danych w prosty sposób pod adresem https://technicalseo.com/tools/schema-markup-generator/.
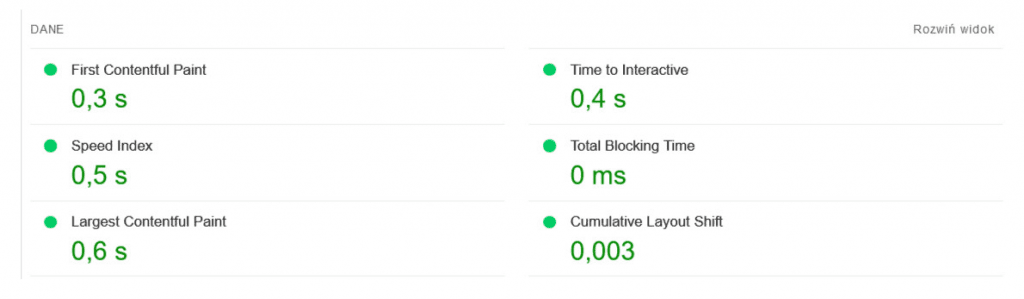
Analiza Core Web Vitals
Pierwszym krokiem w tej analizie będzie sprawdzenie strony w narzędziu https://pagespeed.web.dev/. Oczywiście to nie jedyne narzędzie, które powinniśmy sprawdzić. Podobne informacje znajdziemy w Google Search Console, narzędziu GTmetrix czy Lighthouse w Chrome DevTools.
Niezależnie od którego narzędzia zaczniemy musimy sprawdzić najważniejsze statystyki dla naszej strony:
- LCP (Largest Contentful Paint), to statystyka mierząca czas największego wyrenderowanie i wyświetlenia treści. Główny element strony, np. grafika czy wideo musi się w całości załadować.
- FID (First Input Delay), czyli metryka mierząca opóźnienie przy pierwszym działaniu takim jak kliknięcie, wprowadzenie danych czy wypełnienie formularza.
- CLS (Cumulative Layout Shift) to metryka mierząca stabilność wizualną układu strony. Google traktuje przesuwający się szablon podczas ładowania jako błąd.
- TTI (Time to Interactive) pomiar czasu, który upływa od załadowania strony do momentu uzyskania opcji wprowadzenia danych w serwisie
- TBT (Total Blocking Time) dzięki tej statystyce dowiemy się ile czasu upływa pomiędzy załadowaniem pierwszej treści na stronie (FCP) a uzyskaniem opcji wprowadzenia danych (TTI).
Następnie powinniśmy zapoznać się z wieloma wytycznymi, które oferuje nam chociażby PageSpeed Insights i postarać zastosować się do maksymalnej ilości. Najczęściej spotykane błędy to np. złe dostosowanie rozmiarów obrazów, brak użycia formatów nowej generacji dla grafik, obecność zasobów blokujących renderowanie, brak kompresji tekstu, dużo nieużywanego kodu JavaScript czy CSS, długi wstępny czas reakci serwera czy brak minifikacji CSS i JavaScript.
Audyt powinien zawierać nie tylko listę błędów, ale przede wszystkim proponowane optymalizacje.
Analiza wersji językowych
Tutaj powinniśmy sprawdzić czy wersje językowe są technicznie dobrze wprowadzone na stronie. Po pierwsze każda wersja powinna mieć swój adres URL. Jeśli wersje językowe wyświetlają się na tym samym adresie URL może to prowadzić do komplikacji i braku indeksacji części z nich.
Bardzo dobrą praktyką jest tworzenie menu językowego, które pozwoli nam w szybki sposób przejść na inną wersję językową danej podstrony.
Kolejny aspekt i możliwe, że najważniejszy to poprawne wdrożenie atrybutów hreflang. Jest to kod obecny w sekcji <head> strony wskazujący robotom wyszukiwarek na jakiej wersji się znajduje, jakie inne wersję są dostępne i pod jakimi adresami, a także sugeruje które z wersji powinna być wersją domyślną strony.
Pytanie również w jaki sposób wdrożono wersję językowe. Mamy tutaj 3 opcje:
- każda wersja na innej domenie krajowej
- wspólna domena i wersje językowe w katalogach
- jedna domena i wykorzystanie subdomen dla wersji językowych
Dostrzegam zalety pierwszej wersji – lepsze powiązanie strony z krajowym rynkiem. Może przyspieszyć to pozycjonowanie strony. Minusem jest oddzielny profil linkowy dla każdej z domen.
Wspólna domena i katalogi z wersjami językowymi z kolei pomagają tworzyć wspólny profil linkowy. Jako domenę główną należy jednak wtedy wykorzystać np. rozszerzenie .com, aby nie wiązać domeny ściśle z jednym krajem skoro języków jest więcej. Wtedy nasz budżet na link-building będzie pośrednio wpływał na wszystkie wersje strony.
Ostatnia opcja z wykorzystaniem subdomen jest moim zdaniem najmniej korzystna. Mamy tutaj oddzielne profile linkowe (mimo, że oprogramowanie takie jak Ahrefs może wskazywać na wspólny współczynnik DR) oraz brak domeny krajowej, które pozwoli nam na osiągnięcie lepszych wyników.
Tutaj znajdziesz więcej szczegółów na ten temat oraz inne sposoby implementacji wersji językowych dla Google: https://developers.google.com/search/docs/advanced/crawling/localized-versions?hl=pl
